HBM(High Bandwidth Memory)とは:AIで活躍する半導体メモリ
本記事の内容の一部は、半導体メモリに詳しいエンジニア・東急三崎口さんにご協力いただきました。普段はこちらのブログで発信されています。
HBMとは

HBM(High Bandwidth Memory)は「HBM(High Bandwidth Memory)は、高速かつ広帯域なデータ転送を可能にする次世代DRAM技術・規格」です。複数のDRAMチップを垂直に積み重ねた構造をしています。
HBMは従来のメモリよりも幅広いデータ転送速度(帯域)で動作することから、生成AI用のGPU(Graphic Processing Unit)のメモリとして使用されています。
なお、HBMは、DRAMの一種というよりは、DRAMを高速・広帯域に接続するための構造的・電気的な「規格」です。一般的に、この規格に基づいて作られたスタック型DRAMチップ群をまとめて「HBM」と呼んでいます。
HBMがAI向けGPUで選ばれる理由
HBMがAI用途として重要なのはGPUが膨大なデータを「高帯域・低遅延」で処理できるためです。
キーワードとなる「GPU・帯域・VRAM(HBM)」について順を追って説明します。
GPUとは:CPUとの違い

GPUは「グラフィックス・プロセッシング・ユニット(Graphic Processing Unit)の略で、画像や動画処理を行うための専用プロセッサ(演算装置)」です。
GPUは多くのコアを持ち、大量のデータを同時(並列で)処理することに特化しています。
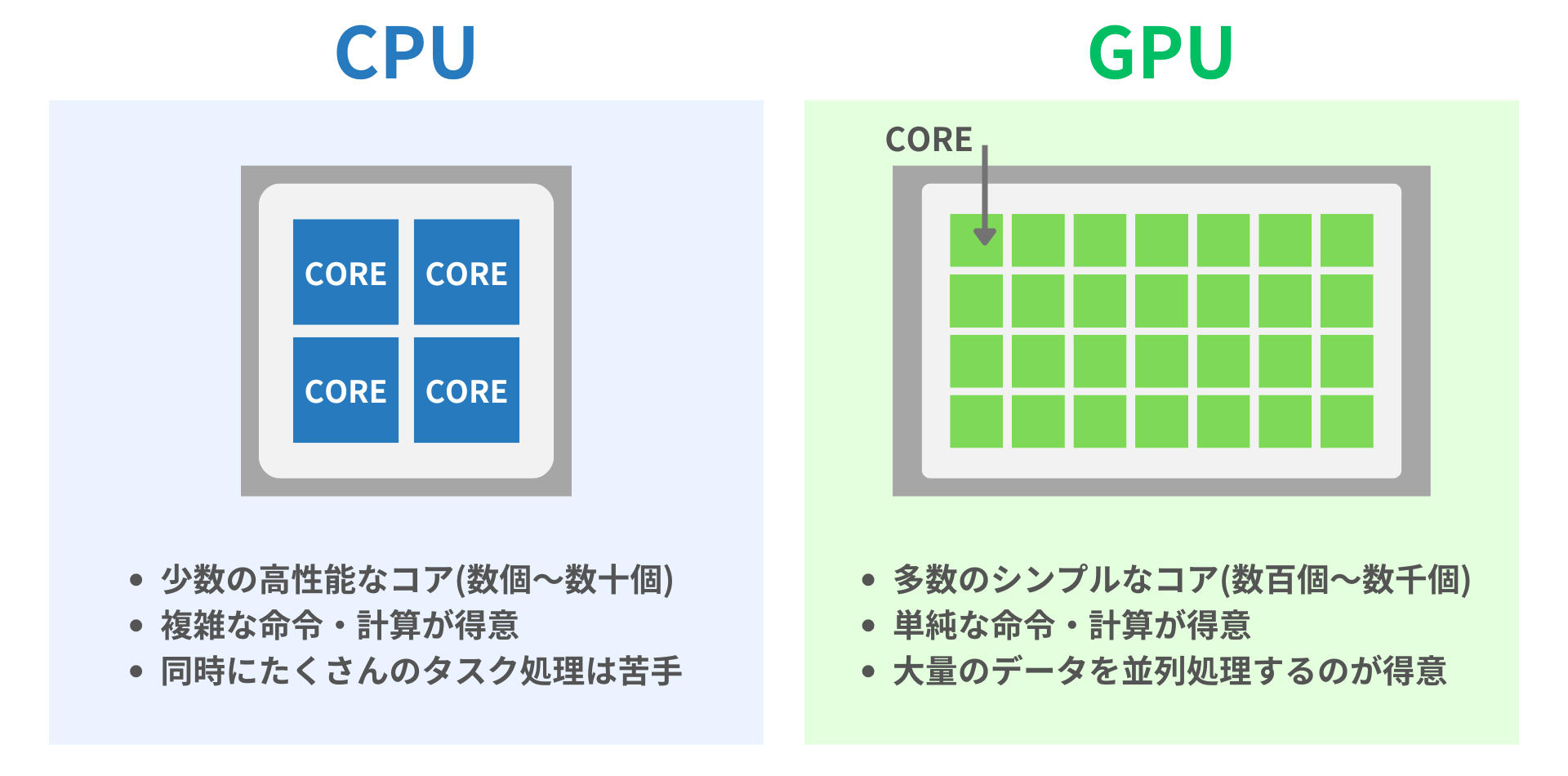
PCのプロセッサとして有名なのはCPUです。CPU通常、数コアから十数コアを持っています(コア:CPUやGPUで実際に計算を行うユニット)。
1つ1つのコアが高性能なため、複雑な計算や命令を実行するのに適しています。一方、基本的には1コア1処理のため、同時にたくさんのタスクを処理することが苦手です。
GPUは数百~数千の非常に多くのコアを持ち、大量のデータを同時(並列で)処理することに特化しています。膨大な量のデータ処理が必要なAIとの相性が良いことから、AI用のチップとして活用されています。
メモリ帯域幅とは

メモリ帯域幅(帯域, memory bandwidth)とは「一定時間あたりに転送できるデータ量のこと」です。プロセッサが半導体メモリからデータを読み取ったり、半導体メモリにデータを格納したりする速度を表します。
例えば、1秒間に100GBのデータを送れる場合、そのメモリの帯域は100GB/sです。
帯域は、大まかに主に以下のような計算式で表されます。
帯域(GB/s) = バス幅(Byte) × 周波数(Hz) × 転送回数/クロック
- バス幅(Byte):一度に何バイトのデータを送れるか(=同時に送れるデータの太さ)
- 周波数(Hz):1秒間に何回データを送るか(転送クロック数)
- 転送回数/クロック:1クロックあたり何回データを転送するか(例:DDRは2回、QDRは4回)
つまり、「速く(高クロック)」かつ「太く(広バス幅)」で、データを送れるほど、帯域は広くなります。
AI用途においては、GPUが高速にデータを読み書きできるよう「高帯域」が求められます。HBMはバス幅(≒並列に走る配線の本数)を広げることで、高メモリ帯域を実現しています。
VRAM(HBM)の役割
GPU用の専用メモリはVRAM(Video RAM)と呼ばれ、現在はHBMが主流です。グラフィックボードはGPUとVRAMで構成されます。
以下はGPUによる演算処理の流れです。
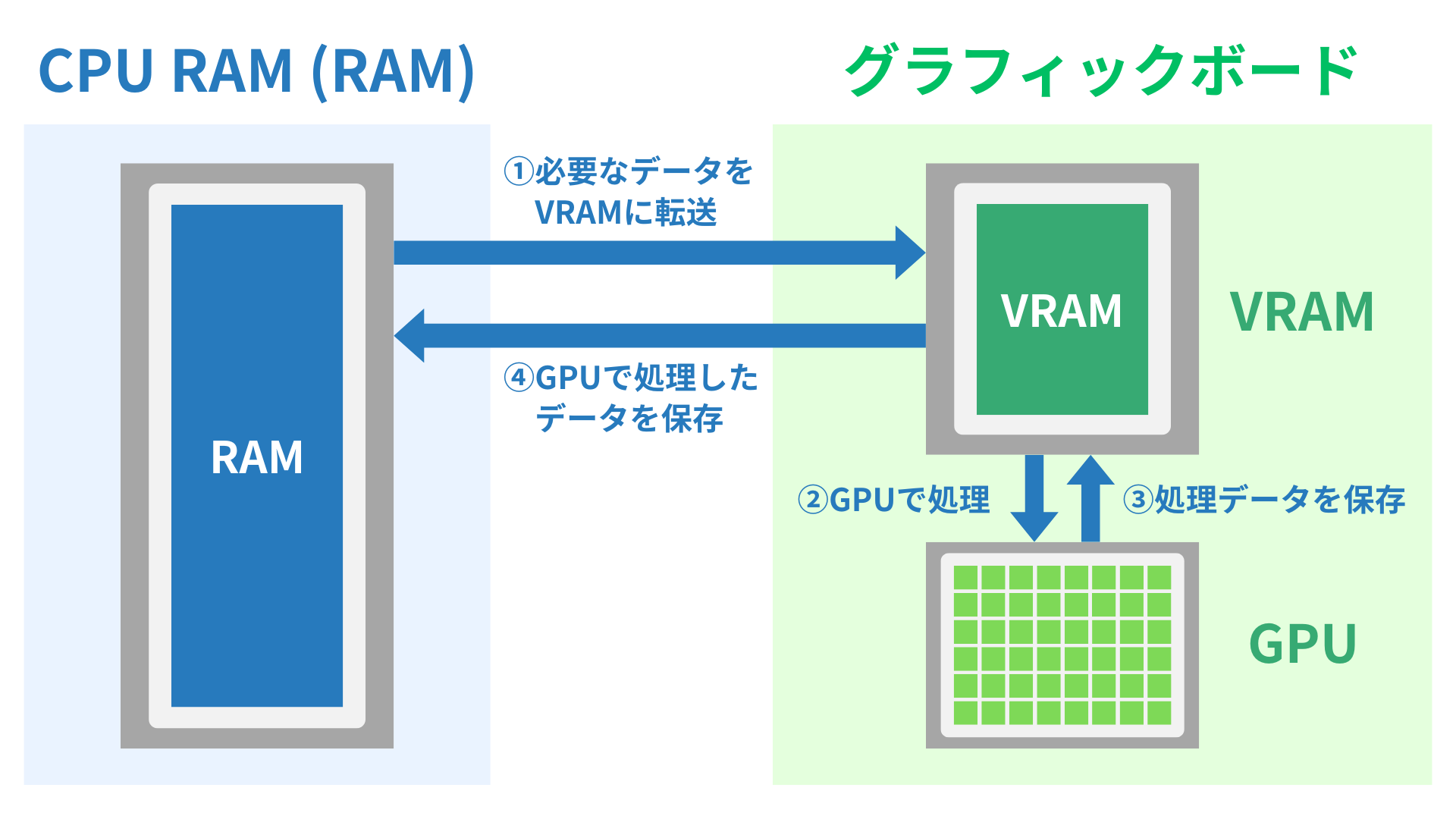
- CPU RAM(RAM)からVRAMに必要なデータを転送
- GPUがVRAMのデータを読み出して処理
- 処理したデータをVRAMに保存
- VRAMのデータをCPU RAMに保存(またはVRAMからそのまま出力)
画像認識や自然言語処理などのAIでは、膨大な量のパラメータや中間データを高速にやり取りしながら演算を行います。
GPUがデータを高速に処理するためにはVRAMが「大量のデータを高速に読み出す・書き出すことができる」点が重要です。
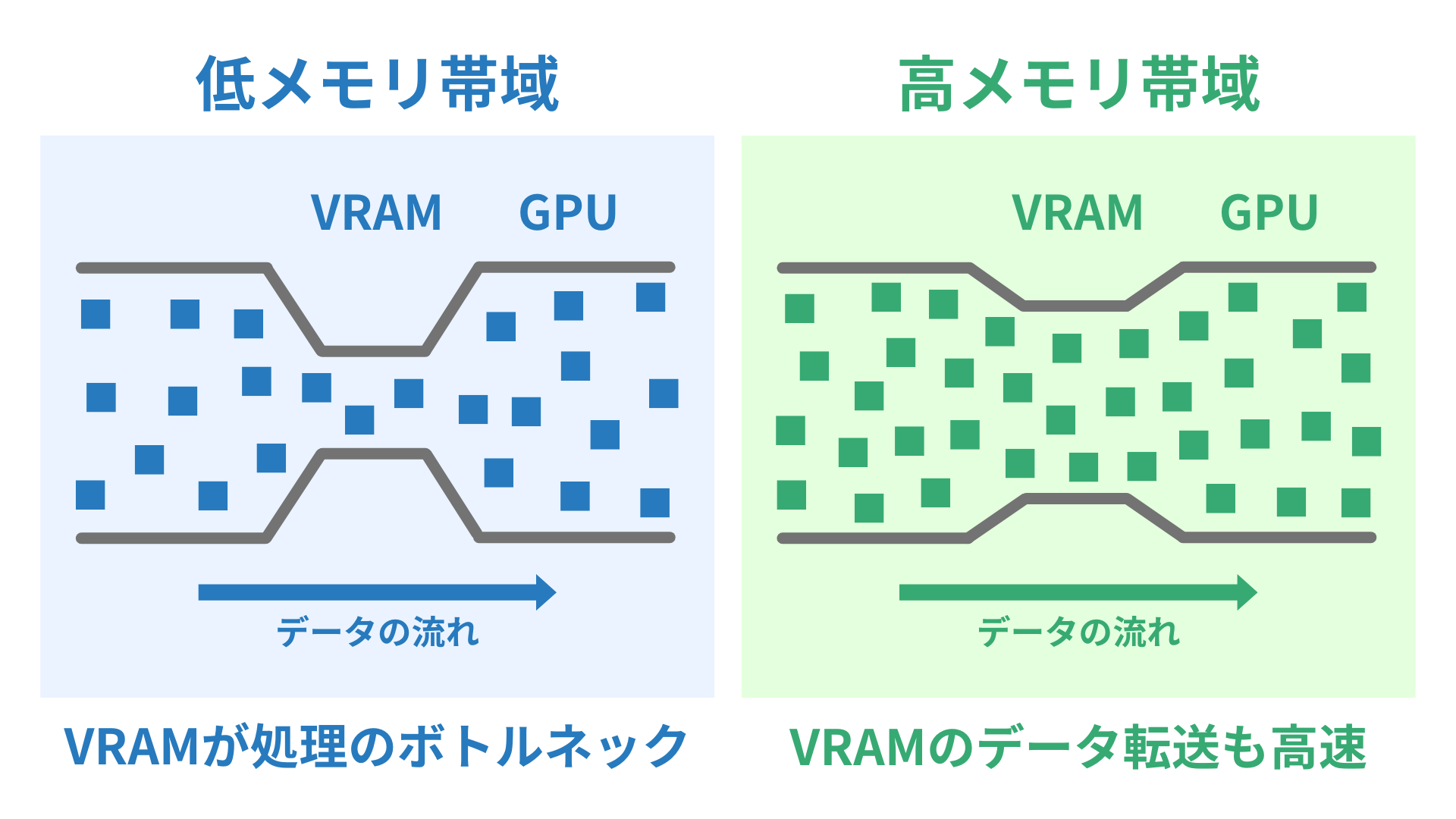
GPUは大量の演算ユニットを並列に動かして処理を加速しますが、肝心のデータが遅れて届くと、演算ユニットが待ち状態になり、性能が出ません(ボトルネック)。
そのため、AI用GPUには「高帯域・低遅延」のメモリとしてHBMが用いられるのです。
HBMの構造
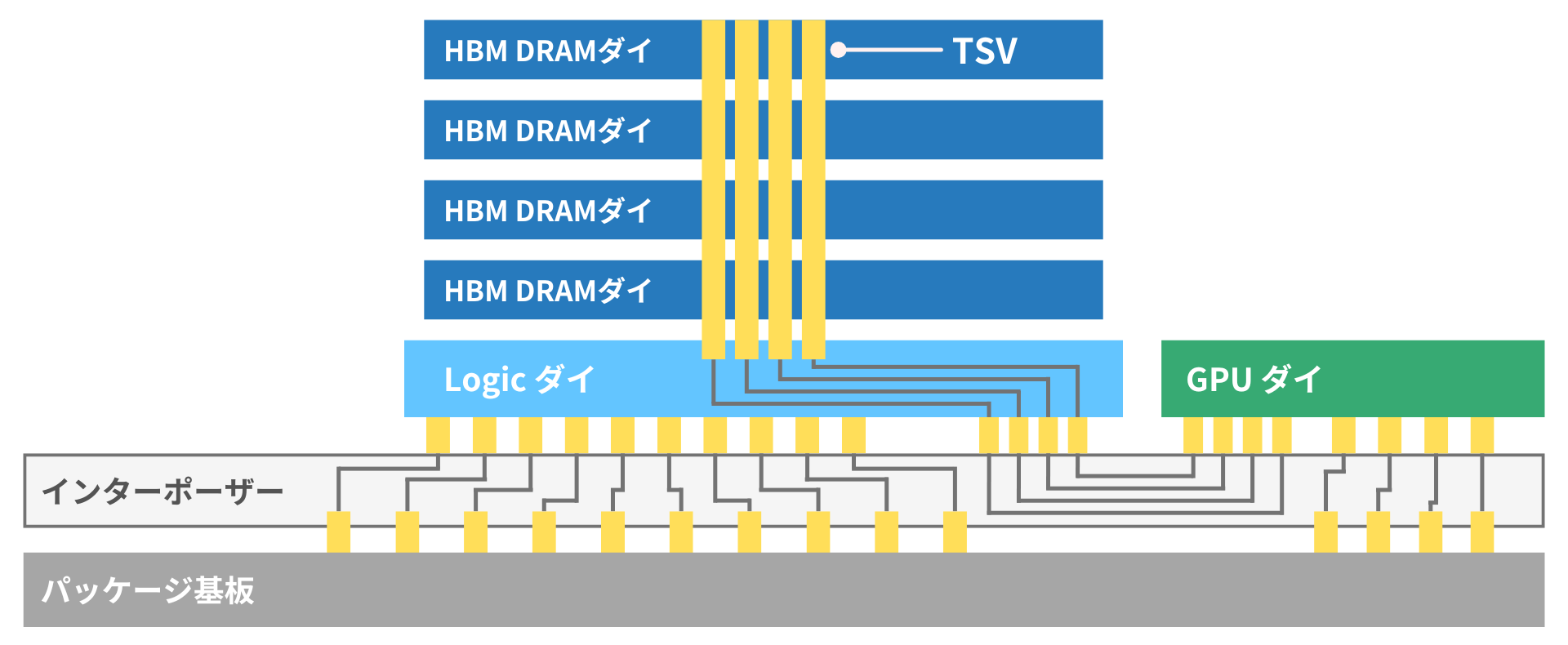
(出典:東京エレクトロンデバイスの資料を参考に筆者作成)
HBMは「DRAMを垂直に積層(3Dスタック)し、シリコン貫通電極(TSV)で接続した構造」をしています。
構造を理解するポイントは以下の3つです。
- スタック:DRAMを垂直に積層し省スペース・大容量化
- TSV(シリコン貫通電極):積層したDRAMを高密度配線で接続=高バス幅
- インターポーザー:HBMとGPUを基板上で接続
この構造により、大容量・高メモリ帯域なHBMを実現し、GPUの処理高速化を達成しています。
スタック
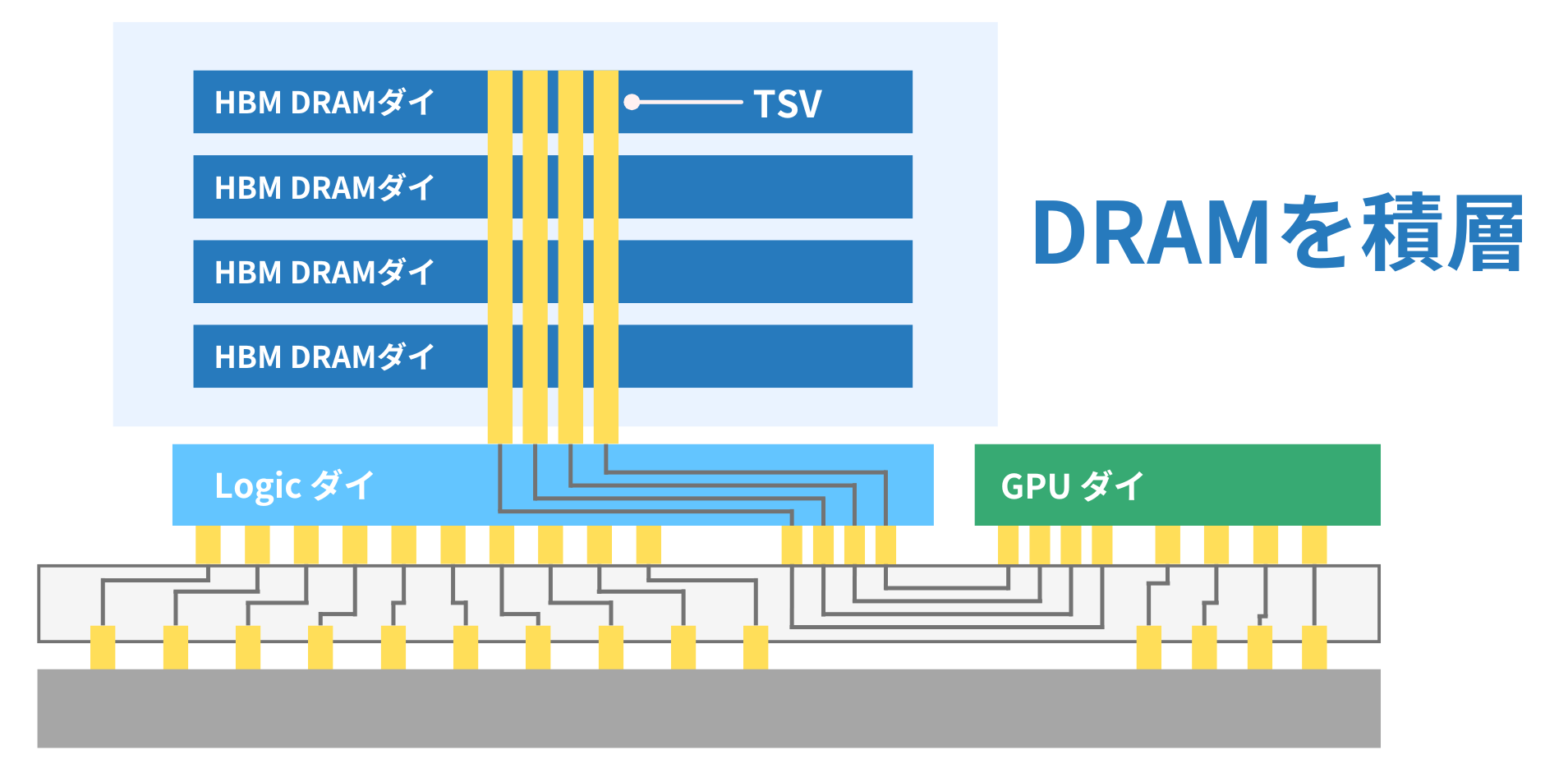
HBMでは、DRAMチップを縦方向に積み上げた「3D積層構造(stacked DRAM)」が採用されています。
これにより、限られた面積で大容量を実現できるだけでなく、高帯域・低消費電力な通信も可能になります。
下図は、従来のGDDRとHBMの構造比較です。
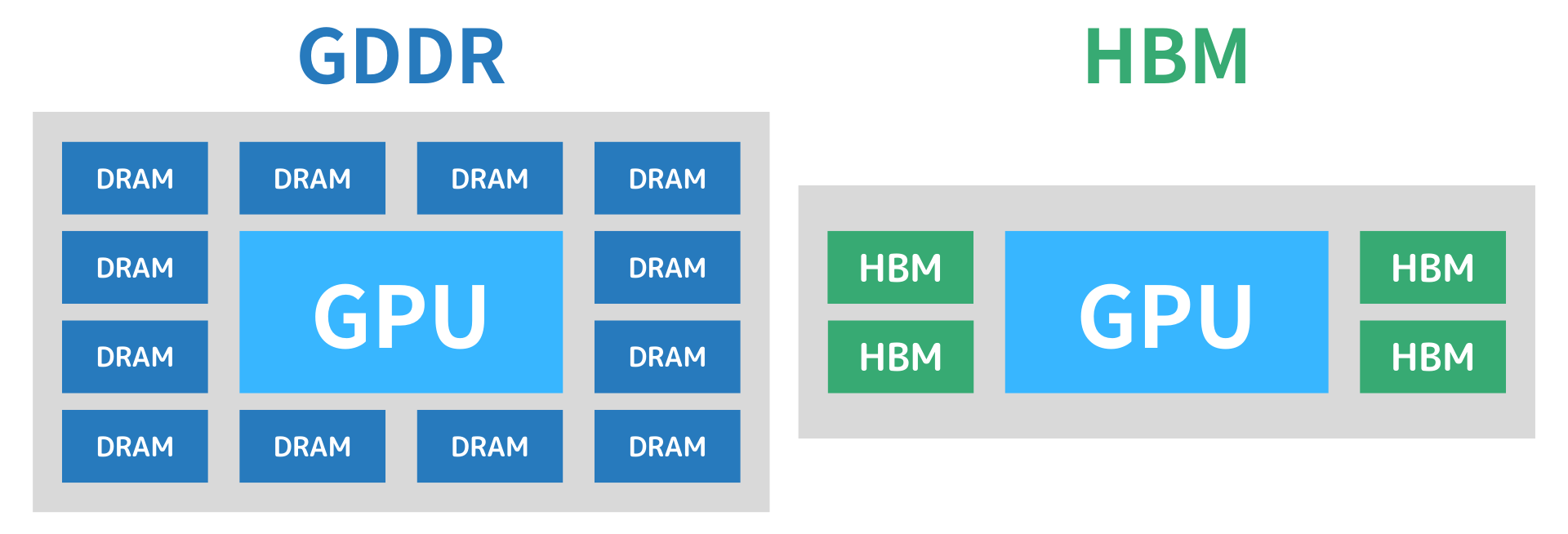
- GDDR
- HBM
複数のDRAMがGPUの周囲に平面的に配置される方式。個々のDRAMとGPUを長い配線で接続するため、面積を多く占有し、信号遅延も大きくなります。
DRAMを垂直に積層したHBMをGPUの近くに配置。積層によって省スペースかつ大容量を実現し、配線距離も短いため、高速かつ低消費電力な通信が可能です。
このように、HBMはDRAMの3D積層と近接配置によって、従来のGDDRよりも高い帯域と電力効率を実現しています。
TSV(シリコン貫通電極)
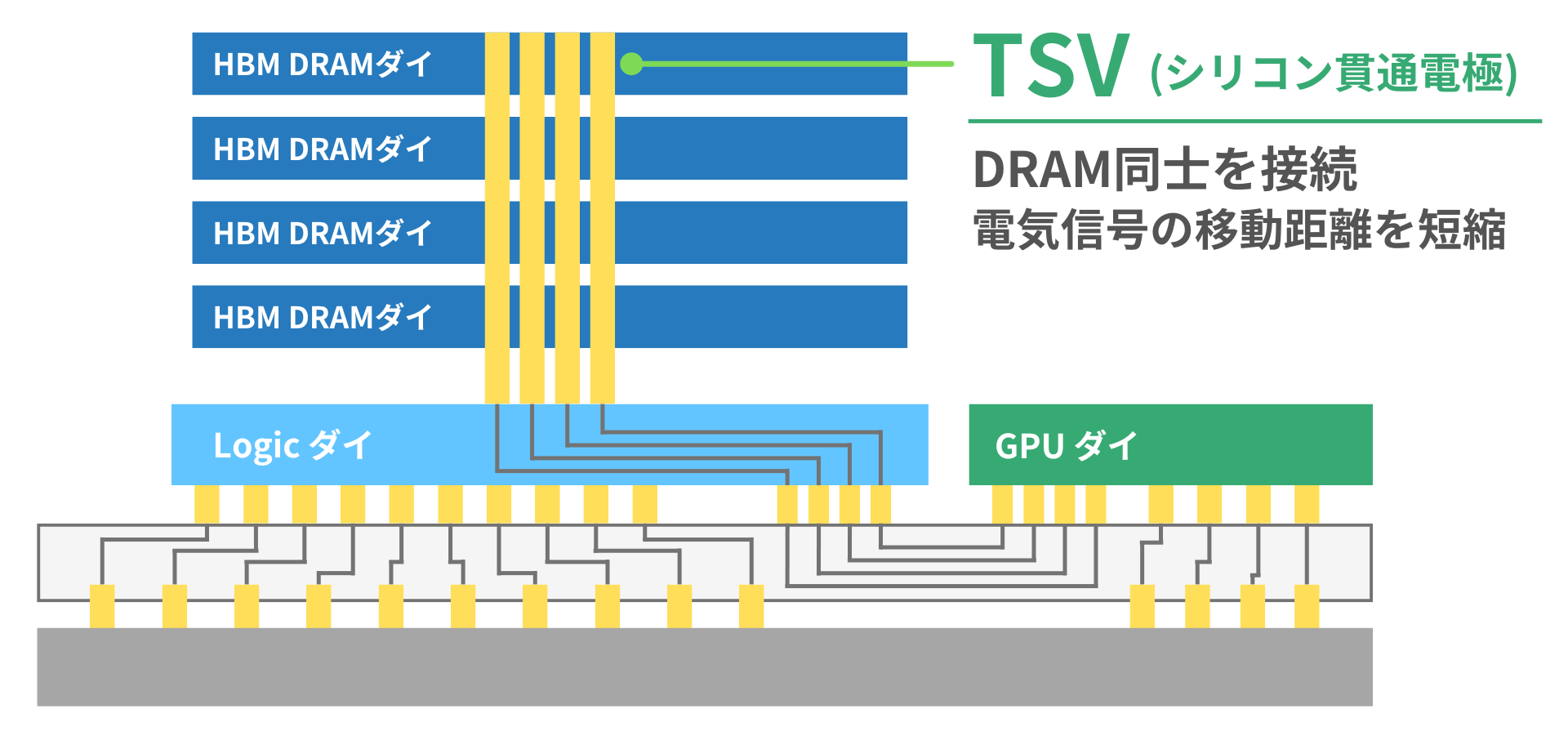
HBMでは、積層したDRAMチップを「TSV(Through Silicon Via:シリコン貫通電極)」によって垂直方向に接続しています。
TSVにより、各DRAM間を直接つなぐことで配線距離を大幅に短縮できます。従来の、DRAMを平面的に並べて接続する方式と比べ、信号の伝送が高速かつ効率的になります。
この構造により、HBMは高密度化・高帯域・低消費電力を同時に実現しています。
インターポーザー
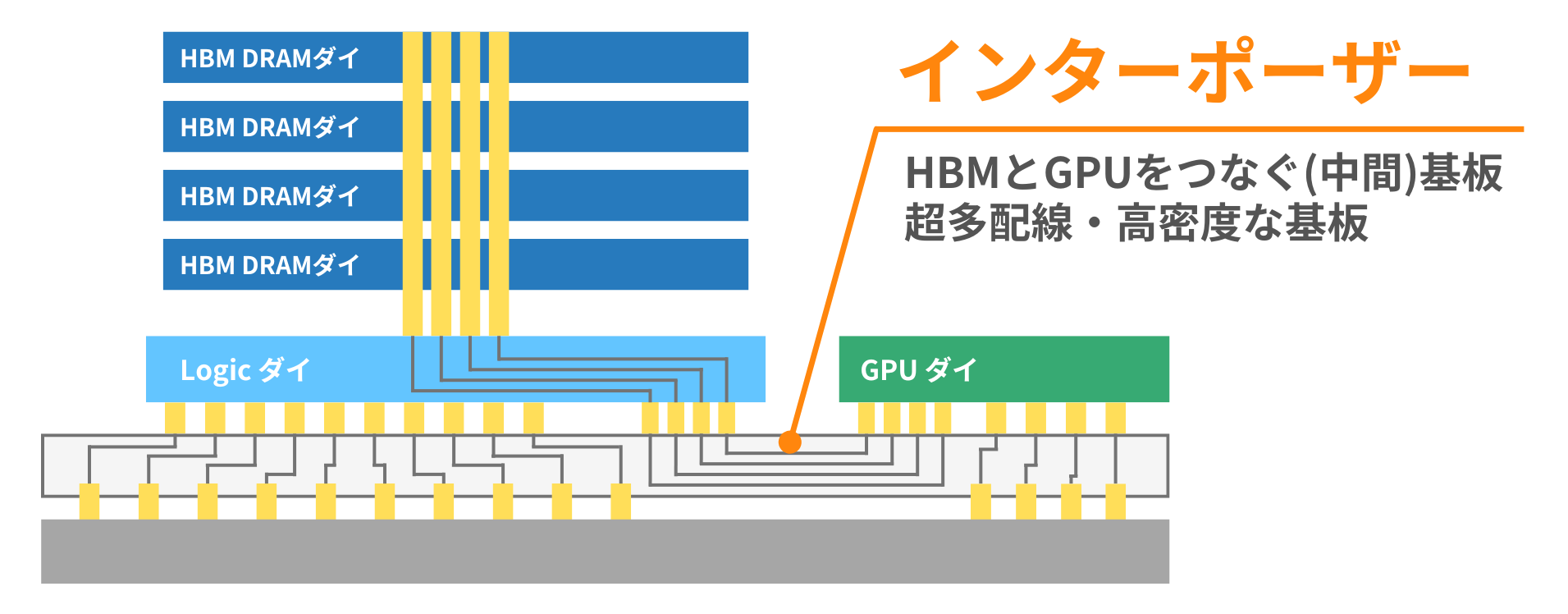
HBMとGPUはインターポーザー(interposer)と呼ばれる中間基板で接続されます。インターポーザーは「HBMとGPUをつなぐための超多配線・高密度なシリコン中間基板」です。
HBMの高速性・広帯域性は、高密度配線による「バス幅を広げること」で実現しています(=高速ではなく「一度に大量に」送る)。
しかし、通常のパッケージでは数千本以上の配線を引くことはできません。そこで、高密度配線なインターポーザーを用いることで、高帯域な転送を実現しています。
すなわち、HBMの帯域性能を活かすために、インターポーザーは不可欠です。
前の講座

Semi-journalの企業スポンサー制度